Introduction
As part of the Frontend Chapter at ProntoPro, my team and I recently refactored our in-app chat, impacting our web, iOS, and Android apps. The refactor took months, required three frontend engineers working on it full time, and involved reimplementing a significant chunk of our legacy codebase. Join me as I share our adventure and explore what helped us complete this challenging project. Hopefully by the end of this post you’ll get some ideas that could prove useful next time you need to perform a similar refactor. I’ll also mention some of our engineering practices which could be helpful in more general cases.
Some More Context
Over the last three months, my team and I refactored a part of our product referred to internally as the pro chat. Its purpose is to connect pros (providers) with consumers, and it is available to pros once they have quoted a request for some particular service. The chat is located in our legacy workspace, and we were tasked with both rebranding it and also moving it to our modern workspace (note that I said “workspace” in reference to Yarn workspaces, as we work with a monorepo).
Here you can see some before/after screenshots of the pro chat:
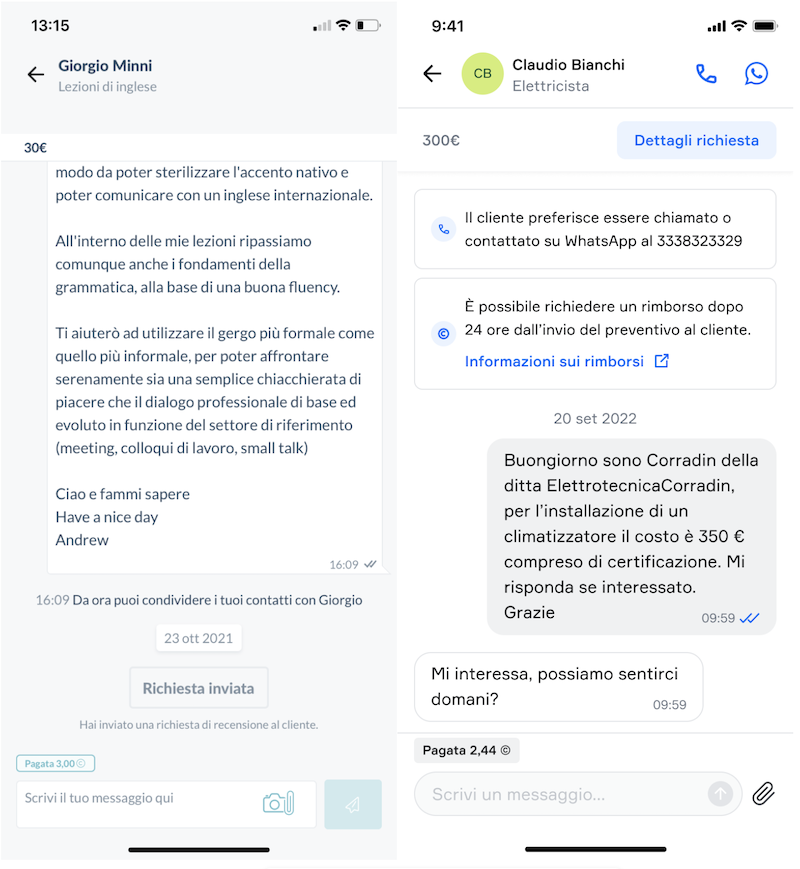
The learnings we drew from this experience can roughly be divided into three categories: technology, process, and people.
Technology
Benefits of a Monorepo
In this project there were two important conceptual locations: the old pro chat with the legacy code we needed to refactor, and the new pro chat with the refactored code we needed to ship. We often needed to go back and forth between these two locations because the pro chat had a lot of logic that we just constantly needed to revisit. Hosting these two locations in the same repository along with all our other code made it extremely simple to navigate between important files in each location (therefore taking maximum advantage of VS Code’s code navigation features).
Benefits of Micro Frontends
Our current infrastructure is divided into four conceptual layers. From a top-down POV we have: Applications, Domains, Libraries, and Tools. We also have a legacy workspace which is a SPA and does not have any such conceptual distinctions (this is where the old pro chat lived). Side note: we’re in the midst of setting up a completely new monorepo (powered by Nx) to host all our frontend code.
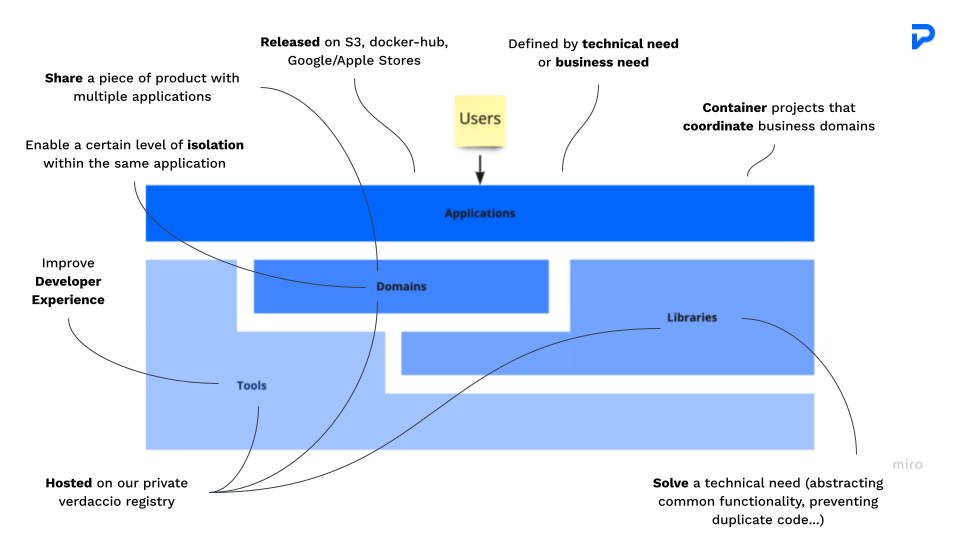
Domains solve technical needs, they enable a distributed architecture and software reusability. Before we started actually refactoring any code, we had to set up the domain which would host the new chat. This included setting up our testing framework, linting checks, commit formatting checks, configuring the CI… Thankfully we already had plenty of such domains in our codebase, so it was just a matter of copy/pasting any one of them and making some slight changes. We called this task the “infrastructure setup”.
Note that with our new monorepo we can use Nx generators to scaffold new projects.
Additionally, an advantage of having both a micro frontend and a monorepo is that we can easily search other domains for existing solutions relating to refactoring legacy code in our main workspace.
Moving Fast With Code Duplication?
As already mentioned, we often found that a problem we were having in the new pro chat was already solved in some other domain. We were able to copy existing solutions without worry because of the framework with which we develop our application, and because of good testing practices.
Using React provides us with reusable components that are by nature easy to plug into any part of the UI. Our components respect the Single Responsibility Principle, which made it easy to pick the individual responsibilities (or features) we wanted to bring into the new chat.
Furthermore, because we have a high level of unit test coverage, most of our components come with tests which we could copy as well. For this reason we were confident that the behavior we were bringing into the new domain was already tested and bug-free.
In summary, high code quality made duplicating code easier since we didn’t need to worry about the quality of the code we were copying.
Note that I am not proposing WET as a good practice, instead we follow the AHA principle. We duplicated code to avoid hasty abstractions due to an engineer’s limited context in a particular team, and to move faster during our product cycle.
Feature Flags and Continuous Delivery in Staging
In ProntoPro we follow trunk-based development. Regarding our frontend repository’s CI/CD, merging in master is equivalent to updating our application in staging (the development environment our QA engineers use to test features before we release them to production).
Once we implemented some basic features in the new pro chat that could be manually tested, we decided to ship the chat to staging under feature flag (so as not to block production deployments). Incrementally delivering small, functional, pieces of the chat to staging allowed our QA team to also incrementally perform manual tests. This brought many benefits such as:
- Allowing us to respond to defects more quickly.
- Avoiding hogging QA engineer capacity to test the entire chat all at once.
- Having our QA engineer be much more involved in the building process.
- Avoiding catching a logic flaw too late, causing a waterfall of changes at the end of the project.
Process
Ensuring Sufficient Engineer Capacity
Allocating sufficient engineer capacity is crucial for any software project. Initially we were just two frontend engineers working on the chat. However, we soon realized that the scope of the project was much larger than estimated. And so we got a third engineer onboard, which allowed us to move exponentially faster.
Sometimes adding an engineer can actually slow down the work. However, we only slightly increased our capacity, and we did so before the project could start running late. This is how we avoided encountering Brooke’s law: “Adding manpower to a late software project makes it later”. Furthermore, given that our workflow is heavily inspired by Basecamp’s ShapeUp method, our engineers are aligned on all domains because we weren’t working with fixed squads at the time (we do now, for reasons unrelated to the scope of this article). Otherwise, onboarding another engineer could have considerably slowed the project.
Adding just one engineer also made it possible to work with a great dynamic: two engineers focused on moving fast and implementing the chat, while another focused on reviewing pull requests. This balanced approach allowed us to find the sweet spot between code quality and time to delivery. Before the third engineer joined, my colleague and I would need to stop whatever we were implementing whenever we had to review each other’s pull requests.
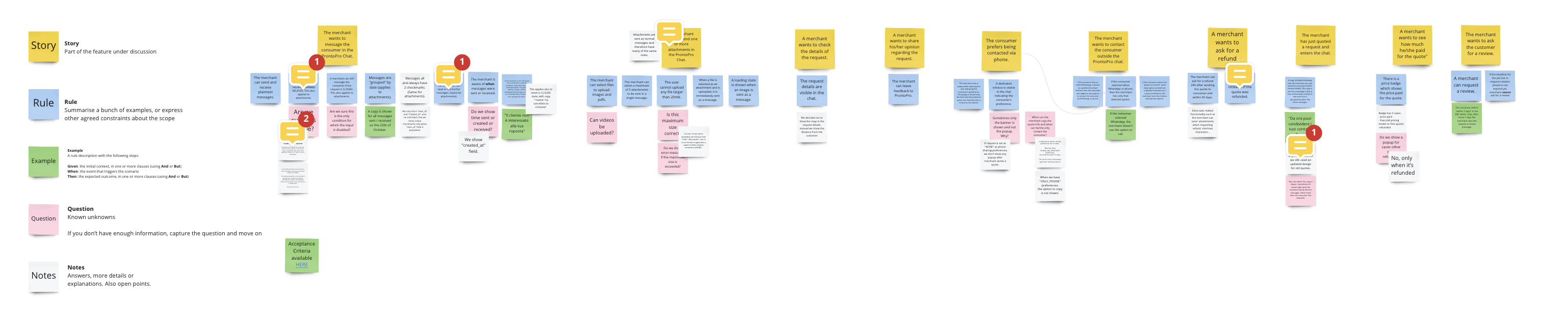
The Search For Acceptance Criteria
As part of our behavior-driven development approach, we often have Example Mapping sessions as one of the first steps in our building phase. The output of such sessions is a set of acceptance criteria that developers can use to develop and testers can use to test. Everyone should be aligned on these criteria following the session. Here is the output of the Example Mapping session for the pro chat:
And here are two user stories in more detail (note that “merchant” is equivalent to “pro”):
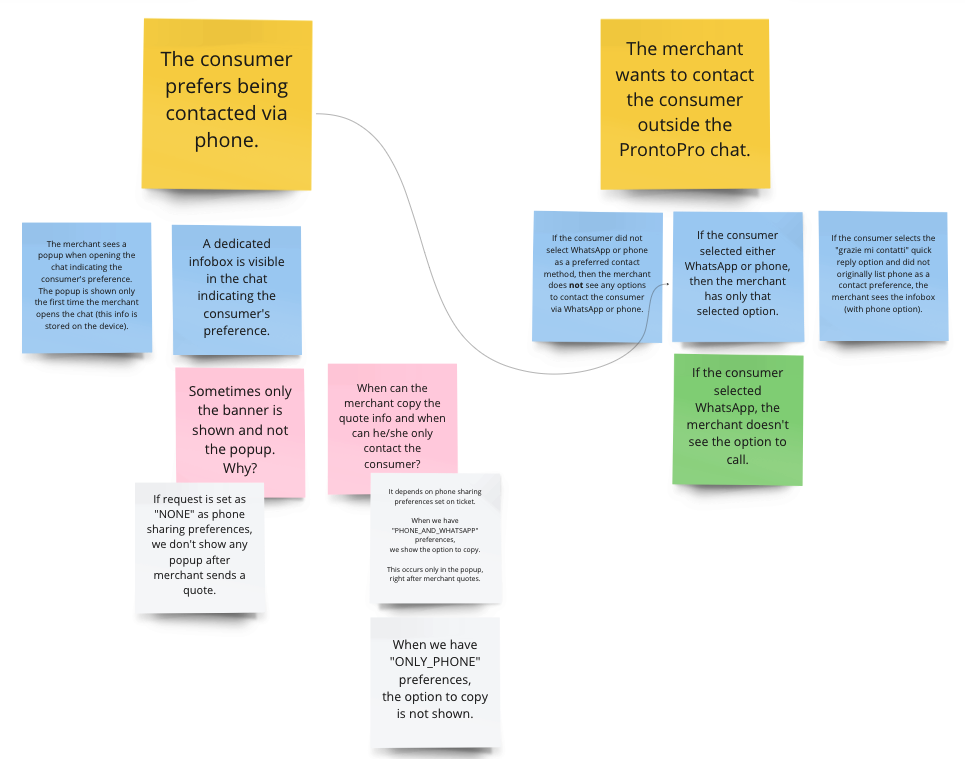
Unlike a new feature where we think of all behaviors from scratch, the pro chat was an edge case for us. It was an existing project with many behaviors, some of which were hard to spot, and only truly discoverable and understandable by digging through legacy code. For this reason the acceptance criteria following our Example Mapping were not sufficient (though definitely helpful). To fix this we organized “20 minute legacy roadtrip” meetings where we would go over legacy logic together to gain a better understanding of the behavior we’d have to reimplement. This also aligned us regarding how the old pro chat worked and made it more bearable to read through legacy code, since we did it together.
Slicing
Another important step in our building phase is slicing. Before writing any code for the new pro chat, we dove deep into a slicing session where we divided our big task into smaller more manageable tasks (tracked in our task management system which is Asana). We decided to divide tasks based on UI components, and have each task correspond to a single pull request, including as much implementation level detail as possible. Basically, when filling in the details of a task, we asked ourselves “what would we do if we had to start implementing this now”. Some useful things we would add to our task descriptions were: written descriptions of component behavior, pseudo-code, links to important files… Here is an example of a task description for the creation of the chat bubble UI component:

Slicing this way also made it extremely easy to knowledge share and onboard new engineers, since any engineer could decide to jump in and pick up any task at any time. In fact, there was basically no onboarding needed for the third engineer that joined us. Again, the minimal onboarding was also easier because we worked with ad hoc squads, so every frontend engineer had a good grasp on each domain.
In the screenshot above, you might have noticed how certain features were singled out as being “non-blocking”. Distinguishing between features required to go to production and “nice to have” features was crucial in helping us move faster with the pro chat implementation. In our case we left small design details and performance optimizations as tasks to complete only at the very end of the project, if we had time for them. These details did not contribute to the definition of “done” for the pro chat, and could be handled in future cycles without impacting the chat user experience.
Strict Code Review on Small PRs
As mentioned earlier, each Asana task became a pull request, and we tried to keep our pull requests as small as possible. This made it more costly to implement a large section of UI since it needed to be broken down into smaller pieces. However, this made the code review process run much smoother. The mental load on the reviewer was limited, and it took less time to review smaller pull requests. Making it quicker to unblock the pull request author by giving quick feedback.
The philosophy here was “slow is smooth, smooth is fast”. Going slow allows for more in depth code reviews, more discussion, more testing, higher quality code… Which prevents defects being found in the staging environment by our QA engineers. On the other hand moving fast would have resulted in more defects in staging, each of which would have required dedicated efforts to fix, thus significantly slowing the project.
Reevaluating Product Functionality
Developers hate legacy code for a reason. Diving back into our codebase it was evident that there were many instances where a developer jumped in to add some functionality without reading the surrounding code. Many times we noticed the same check being performed more than once, or a long list of random checks haphazardly put together.
When reimplementing the logic it was incredibly useful to work closely with product figures in order to confidently throw away logic that no longer served any purpose. On more than one occasion our QA engineer confirmed to us that we could throw away and not reimplement a certain section of legacy code.
People
Culture Counts
As a final note, the culture we have in ProntoPro and our engineering department also acted as an enabler for us. As engineers, we already put enough pressure on ourselves, so it was helpful to not feel additional pressure from other stakeholders when we went over the initial estimates.
When pairing with my colleagues it was also great to work with people that are enjoyable to talk to. Whatever time of day we were meeting we could always find an agreement and slip in a joke or two. That’s why you should never underestimate the culture fit when recruiting, because a good engineer can learn new technologies but it’ll be harder for them to change their personality if it doesn’t fit your company culture.
Conclusion
Refactoring is more than just rewriting code. The edge cases of a large refactor can stress test a product company’s cemented practices for building new features, challenging those involved in finding ways to improve processes whose results should not be taken for granted.
Our team needed three months to complete the pro chat refactor, which is double the initial estimate. The pro chat is big, had a lot of logic to discover, and was all legacy code. However, considering that three frontend engineers worked full time for three months on this project, introducing mountains of new code: in the end, our QA team found only a few defects in staging and only one minor bug in production. Credit goes to the technology, process, and people enablers we will continue to invest in to keep tackling more and more ambitious projects in ProntoPro, such as the replatforming efforts involving our brand new frontend monorepo.